I have to move my harbor instance to a new cluster.
- old cluster – find all the PVC’s
kubectl -n harbor get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-harbor-harbor-redis-0 Bound pvc-aebe5589-f484-4664-9326-03ff1ffb2fdf 5Gi RWO pure-block 24m
database-data-harbor-harbor-database-0 Bound pvc-b506a2d4-8a65-4f17-96e3-f3ed1c25c56e 5Gi RWO pure-block 24m
harbor-harbor-chartmuseum Bound pvc-e50b2487-2a88-4032-903d-80df15483c37 100Gi RWO pure-block 24m
harbor-harbor-registry Bound pvc-923fa069-21c8-4920-a959-13f7220f5d90 200Gi RWO pure-block 24m- clone in the FlashArray
Find each PVC listed when you run the above command, you may either create a snapshot or a full clone. - Bring up the new app with the same sized PVC’s on your new cluster.
kubectl -n harbor scale deployment --replicas 0 -l app=harbor- scale app to 0 replicas on the new k8s cluster (example above)
- Clone and overwrite each volume on the FlashArray. Using the pvc volume name from the new cluster.
kubectl -n get pvc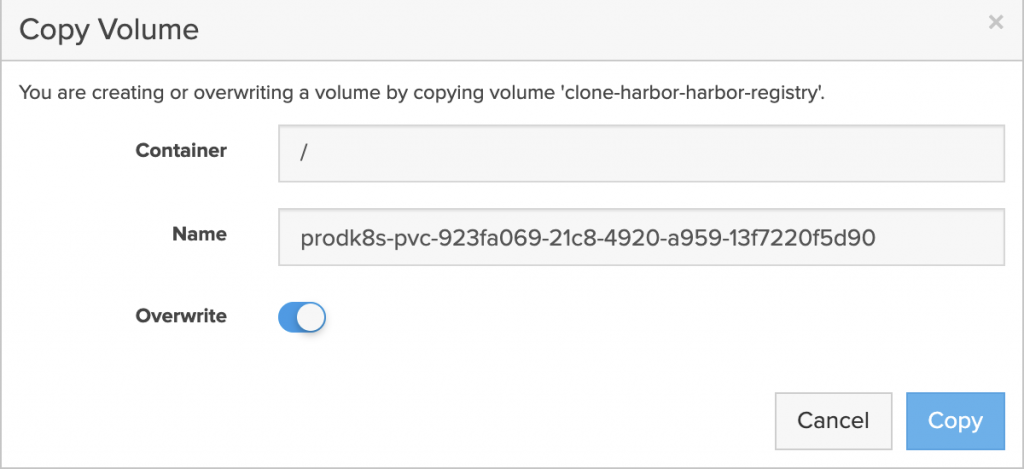
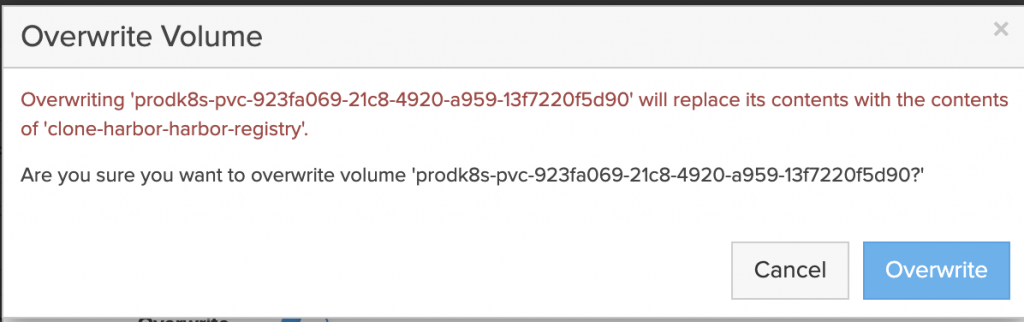
- Scale app back to the required replicas. Verify it works.
kuebctl -n harbor scale deployment --replicas 1 -l app=harbor- Point DNS to new loadbalancer/ingress
kubectl -n harbor get ingresses
NAME HOSTS ADDRESS PORTS AGE
harbor-harbor-ingress harbor.newstack.local,notary.newstack.local 10.xx.xx.xx 80, 443 32mChange DNS to the new cluster.
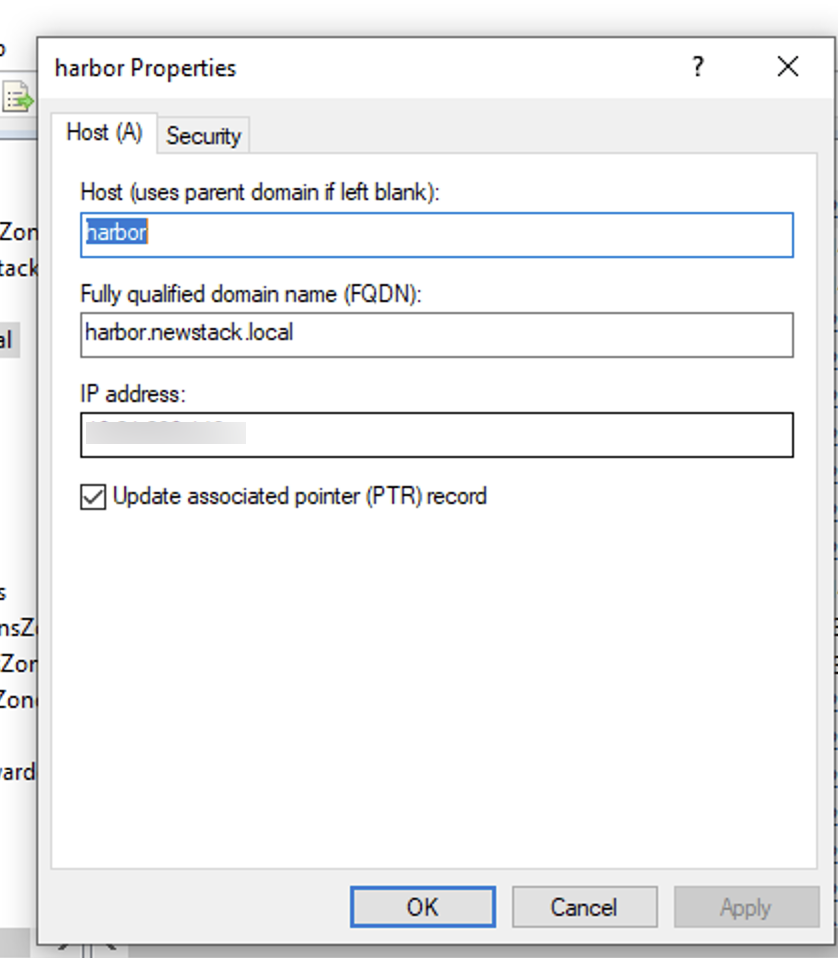
All my data is now migrated